

この記事はstring.strip()メソッドと正規表現パターンを用いて、テキストから記号を除去する|Pythonの続き
引き続き、人間失格を題材にテキスト処理について勉強する
今回は、記号を除去したテキストに対してmecab-python3を用いた形態素解析を行う
用いるテキストファイルの情報
底本:「人間失格」新潮文庫、新潮社
1952(昭和27)年10月30日発行
1985(昭和60)年1月30日100刷改版
初出:「展望」筑摩書房
1948年(昭和23年)6〜8月号
入力:細渕真弓
校正:八巻美惠
1999年1月1日公開
2011年1月9日修正
青空文庫作成ファイル:
このファイルは、インターネットの図書館、青空文庫(http://www.aozora.gr.jp/)で作られました。入力、校正、制作にあたったのは、ボランティアの皆さんです。
「図書カード:人間失格」 https://www.aozora.gr.jp/cards/000035/card301.html (最終閲覧日2024/11/26)
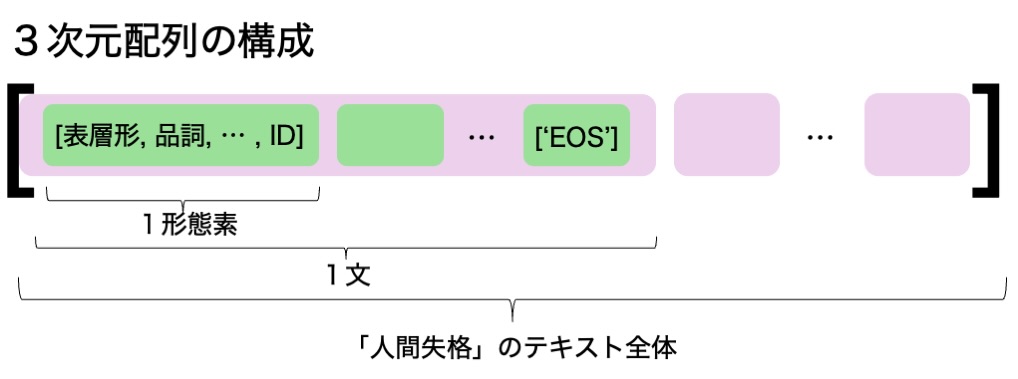
目標
下図のような3次元リストを目指す
最下層:形態素情報のリスト
1つ上の層:形態素のリスト、文末を示す’EOS’がリストの末尾に入る
最上位層:文のリスト
ソースコード
import re
import MeCab
# ファイルの読み込み
filepath = 'r-ningen_shikkaku.txt'
with open(file=filepath, mode='r', encoding='shift_jis') as f:
textlist = f.readlines()
# テキスト処理
pattern = re.compile(pattern=r'《.*?》|||[#.*?]')
textlist = [pattern.sub(repl='', string=s.strip()) for s in textlist] # リスト内包表記
# 形態素解析
tagger = MeCab.Tagger()
pattern = re.compile(pattern=r'\t|,')
result = []
for l in textlist:
keitaiso = [s for s in tagger.parse(l).split('\n')if s] # 文を形態素解析して形態素ごとに分割
keitaiso_info = [pattern.split(string=s) for s in keitaiso] # 各形態素を情報ごとに分割
result.append(keitaiso_info)
print(type(result))
print(len(result))これまでの知識にforループを組み合わせる
ファイルの読み込み→テキストファイルを読み込む|Python
テキスト処理→string.strip()メソッドと正規表現パターンを用いて、テキストから記号を除去する|Python
形態素解析→mecab-python3で形態素解析した文をリストに格納する|Python
変更した点として、19行目のリスト内包表記にif文を追加した
これによって、空白文字を削除できる(strクラスは空文字の場合False、それ以外はTrueを返すため)
実行結果
リストの中身を表示すると表示量が膨大になってしまうので、型と長さだけを出力する
<class 'list'>
858858は文の数を表す
おわりに
今後は形態素解析した結果について単語数や品詞の種類などを集計してみたい
コメントを残す