

この記事はPandasを用いた箱ひげ図の作成|Pythonの続き
今回はヒストグラムを作成する
この記事は、以下の著作物を改変して利用しています。
あいちの人口(2024年9月1日現在) 愛知県人口動向調査結果 月報、愛知県、クリエイティブ・コモンズ・ライセンス
表示2.1日本(http://creativecommons.org/licenses/by/2.1/jp/)
はじめに
ヒストグラムの作成に、今回はdataframe.plot.hist()メソッドを用いる
dataframe.hist()というメソッドでも同じように描けるらしい
データは愛知県の市町村の人口データとするため、区のデータを除外する必要がある
今回は、str.endswith()メソッドを用いる
ヒストグラムの作成
ソースコード
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
# データの読み込みと抽出
df = pd.read_csv('population.csv', encoding='shift_jis')
df = df[(df["国籍区分"]=="a)日外") & (df["性別"]=="a)男女")]
# 区と県全体のデータを除外
df = df[~df['区町村'].str.endswith(pat='区')][1:]
# ヒストグラムの描画
axes = df.plot.hist(column='20240901', bins=25)
axes.ticklabel_format(axis='x', style='plain')
plt.xlabel('人口')
plt.ylabel('市町村数')
plt.show()endswith()
pandas.series.str.endwith()は、文字の終端が一致するかどうかを調べるメソッド
今回は’区町村’列から「〜区」という文字列を調べている(一致すればTrue)
さらに、’~’を先頭につけることで、bool型のSeriesの論理否定をとっている
つまり、「〜区」の行がFalseでその他はTrueとなる
今回のコードでは、さらに県全体のデータも除外するため、スライスで2行目以降を指定している
plot.hist()
column引数で使用する列のラベルを指定する
bins引数でビンの数を指定する(デフォルトは20)
数値を大きくすると、階級区分がより細かくなる
今回は25に指定した
返り値としてmatplotlib.axes._axes.Axesクラスを返す
ticklabel_format()
このメソッドなしでサンプルコードを実行すると、人口が指数表示されてしまう
これを通常表示にするために、axisをx、styleをplainに指定する
実行結果
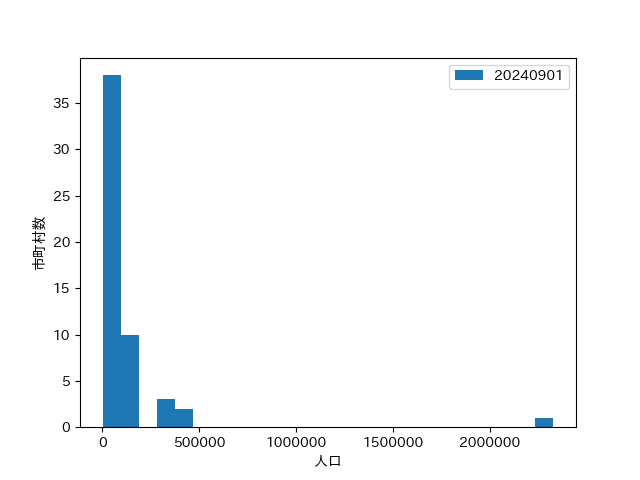
名古屋市の人口がずば抜けて多いことがよく分かる
一方で、それ以外の市町村は50万人以下で、分布もわかりにくいという結果になった
おわりに
これでpandasのグラフ描画は一通り終わったということにする(2変数あれば散布図なども作れそうだが)
今後は、データフレームの操作(計算)系の勉強をしていきたい
おまけ
名古屋市を除いたバージョンも作成した
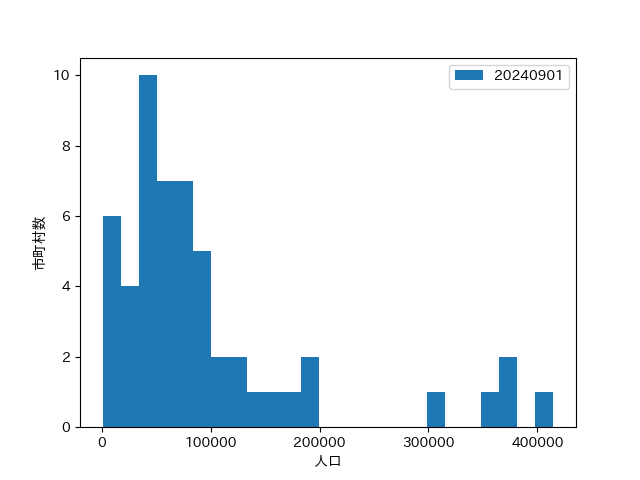
人口30万人以上の市町村の数は5(名古屋市を除く)だと読み取れる
ほかにもヒストグラムでは、箱ひげ図からは分からない最頻値などの情報が読み取れる
コメントを残す