

はじめに
機械学習の勉強として、LSTMを用いたヘイトスピーチ識別モデルの構築を行いました。
ヘイトスピーチ識別は、SNSやオンライン掲示板などに投稿される不適切な発言を自動的に検出する技術です。本記事では、その一助となるテキスト分類モデルの構築を目的としました。
本モデルでは、まずテキストデータに対してトークン化(形態素解析)を行い、語彙の構築を実施しました。各単語を単語IDへと変換し、数値データとして扱える形式に整形しています。これにより、文章をニューラルネットワークへ入力可能なデータへと変換しました。
モデル構造としては、Embedding層とLSTM(Long Short-Term Memory)を組み合わせたニューラルネットワークを採用しました。Embedding層では単語IDを分散表現ベクトルへ変換し、単語間の意味的な関係性を学習します。その後、LSTM層により単語の出現順序や前後関係といった文脈情報を考慮しながら特徴を抽出し、最終的にヘイトスピーチか否かを分類します。
学習の結果、評価データに対して約85%の精度でヘイトスピーチを識別できることを確認しました。
プログラムをGithubに公開しています(こちら)。
実行環境
- OS: Windows 11
- Python: 3.12.12
- GPU: NVIDIA GeForce RTX 5070 Ti
- CUDA Version: 12.9
データセット
本記事では、機械学習・データ分析プラットフォームである Kaggle より公開されている Combined Hate Speech Dataset を使用しました。本データセットは、既存の3つのヘイトスピーチ検出用データセットを統合したもので、合計48,049件のテキストデータから構成されています。
統合に使用されたデータセットは以下の3つです。
- Waseem & Hovy によるTwitterデータ(16,672件)
人種差別(racism)および性差別(sexism)を含むツイートデータ。 - Impermium によるコメントデータ(6,594件)
複数のプラットフォームから収集された侮辱的コメント(insulting comments)を含むデータ。 - DavidsonらによるTwitterデータ(24,783件)
ヘイトスピーチ(hate speech)および攻撃的言語(offensive language)を含むデータ。
これら3つのデータセットは統合後にあらかじめシャッフルされており、前処理は施されていない生データの状態で提供されています。
データ形式はCSV形式で、以下の2列を持ちます。
- text列:投稿されたテキスト本文
- class列:ラベル情報(0 = non-hateful、1 = hateful)
本研究では、データセットを以下の割合で分割しました。
- 訓練データ(train):80%
- 検証データ(validation):10%
- 評価データ(test):10%
それぞれの役割は以下の通りです。
- 訓練データ:モデルのパラメータを学習するために使用
- 検証データ:ハイパーパラメータの調整およびモデル選択に使用
- 評価データ:最終的なモデル性能を測定するために使用
このようにデータを分割することで、学習時の過学習を防ぎつつ、未知データに対する汎化性能を適切に評価できるようにしました。
モデルの学習
テキストの前処理
まず最初に行ったのがテキストの前処理です。
ニューラルネットワークは数値データしか扱えないため、文章を数値ベクトルへ変換する必要があります。その準備として、トークン化を行いました。
具体的には以下の処理を行っています。
- すべて小文字に統一
- ピリオドやカンマなどの記号を削除
- URL(
httpから始まる文字列)の削除 - メンション(
@から始まる文字列)の削除
今回使用したデータセットは生データのため、SNS特有のURLやメンションが多く含まれていました。これらはヘイトスピーチ判定に直接関係しないケースが多いため、削除しています。
エンコーダー(語彙構築と数値化)
次に、トークン化した単語を数値へ変換するエンコーダーを作成しました。
まず訓練データから語彙を構築します。訓練データ中に出現する単語をすべて収集し、それぞれに一意のIDを割り当てました。
また、未知の単語が出現する可能性があるため、
<OOV>(Out Of Vocabulary:未知語用トークン)<PAD>(パディング用トークン)
を定義しました。
各文章は単語IDの列へと変換されますが、文章ごとに長さが異なります。ニューラルネットワークへ入力する際は系列長を揃える必要があるため、最大長を設定し、それより短い文章には <PAD> のID(0)を使ってパディングを行いました。
これにより、すべての入力を「固定長ベクトル」として扱えるようになりました。
LSTMによる分類モデル
本記事では系列データを扱うため、LSTM(Long Short-Term Memory)を使用しました。LSTMはRNN(リカレントニューラルネットワーク)の一種で、単語の前後関係を考慮しながら情報を保持できるモデルです。
モデルの流れは以下の通りです。
- Embedding層
単語IDを64次元の連続値ベクトルへ変換します。
これはPyTorchのnn.Embeddingを用いて実装しました。
単語を分散表現へ変換することで、意味的な類似性を学習できるようになります。 - LSTM層
単語列を順番に処理し、文脈情報を考慮した特徴量を抽出します。 - 全結合層(Linear層)
LSTMの最終隠れ状態を入力し、1次元の出力値を得ます。
最後にシグモイド関数を適用し、そのテキストがヘイトスピーチである確率を算出しました。
学習設定
学習の設定は以下の通りです。
- 損失関数:Binary Cross Entropy with Logits Loss
二値分類タスクに適した損失関数で、内部でシグモイド関数を考慮した設計になっています。 - 最適化手法:Adam
Adamは確率的勾配降下法(SGD)を拡張した手法で、学習率をパラメータごとに適応的に調整します。
学習率は 0.001 に設定しました。 - バッチサイズ:32
- エポック数:10
訓練データをミニバッチに分割して学習を行い、各エポック終了後に検証データで損失と正解率を評価しました。
さらに、検証データの損失が最も小さくなったタイミングのモデルを保存することで、過学習を抑制しました。
結果
モデルの学習
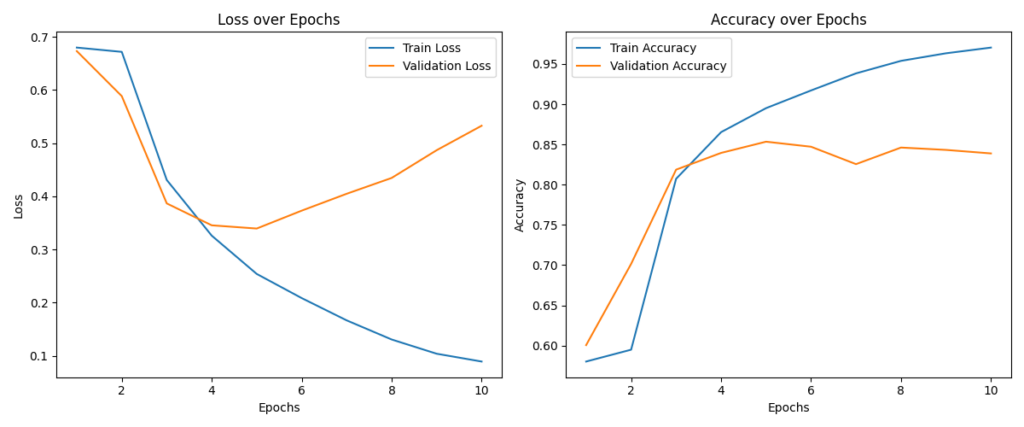
学習曲線を見ると、エポック数5までは訓練データ・検証データともにAccuracyが順調に上昇しており、モデルが適切に学習できていることが分かります。
しかし、エポック数6以降になると、訓練データのAccuracyは上昇、検証データのAccuracyは低下し始めました。
モデルが訓練データに過度に適応し、未知データへの汎化性能が低下する過学習が確認できました。
そのため、この後では検証性能が最も高かったエポック数5のモデルを最終モデルとして採用しました。
評価データに対する結果
前節で選択した最終モデルを用いて、評価データに対するヘイトスピーチ識別を行いました。評価指標の計算には、Pythonの機械学習ライブラリである scikit-learn を使用しました。
全体の性能
- Accuracy:0.8527(約85%)
評価データ4,806件に対して、約85%の精度で識別できました。
学習段階で得られた性能が、未知データに対しても概ね維持されていることが分かります。
混同行列の分析
混同行列の結果は以下の通りです。
| 予測0(non-hateful) | 予測1(hateful) | |
|---|---|---|
| 真0(non-hateful) | 1785 | 301 |
| 真1(hateful) | 407 | 2313 |
この表の見方は以下の通りです。
- 非ヘイトを誤ってヘイトと予測した件数:301件
- ヘイトを見逃した件数:407件
各クラスの評価指標
| Precision | Recall | F1-score | Support | |
|---|---|---|---|---|
| 0(non-hateful) | 0.8143 | 0.8557 | 0.8345 | 2086 |
| 1(hateful) | 0.8849 | 0.8504 | 0.8673 | 2720 |
| Accuracy | 0.8527 | 4806 | ||
| Macro Avg | 0.8496 | 0.8530 | 0.8509 | 4806 |
| Weighted Avg | 0.8542 | 0.8527 | 0.8530 | 4806 |
- Macro Average:F1 ≈ 0.85
- Weighted Average:F1 ≈ 0.85
クラス間で大きな性能差は見られませんでした。
まとめ
本研究では、LSTMを用いたヘイトスピーチ識別モデルの構築を行いました。
まず、テキストの前処理としてトークン化および語彙構築を実施し、文章を単語ID列へと変換しました。その後、Embedding層とLSTM層を用いることで、単語の意味情報と文脈情報を考慮した文の特徴表現を学習しました。
学習曲線の分析から、エポック数6以降で過学習の傾向が確認されました。そのため、検証性能が最も高かったエポック数5のモデルを最終モデルとして採用しました。
最終的に、評価データに対して以下の性能を達成しました。
- Accuracy:0.8527
- F1-score(クラス1:ヘイト):0.8673
この結果から、LSTMを用いた比較的シンプルな構成であっても、一定の精度でヘイトスピーチを識別できることが示されました。
今後の改善として、まず挙げられるのは事前学習済み言語モデルの活用です。
例えば、BERT のようなTransformerベースのモデルをエンコーダーとして利用すれば、より豊かな文脈情報を表現できる可能性があります。LSTMと比較して長距離依存関係の学習に強く、微妙なニュアンスや皮肉表現の理解向上が期待できます。
また、以下のような改良も考えられます。
- ドロップアウトなどの正則化手法の導入
- 重み減衰(Weight Decay)の活用
- 学習率や埋め込み次元数などのハイパーパラメータ最適化
- クラス不均衡への対応(重み付き損失関数など)
今回の実装を通して、自然言語処理における前処理や、系列モデルの基礎的な実装方法について理解を深めることができました。